
Недавно мы столкнулись с проблемой чрезмерного роста базы VMware vCenter Server.
Все началось с того, что один из серверов ESXi в нашей тестовой лаборатории упал в ‘пурпурный экран смерти’.
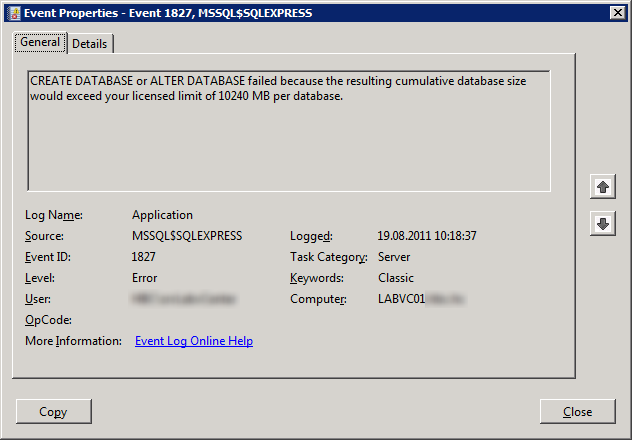
По коду ошибки удалось определить и устранить проблему, однако, после перезагрузки никаких журналов событий на сервере ESXi не сохранилось. Было решено вести централизованный сбор журналов с помощью vSphere Management Assistant. Сказано — сделано, несколько команд в консоли (решили заодно собирать журналы с сервера vCenter), проверка, что журналы в vMA обновляются, и о проблеме забыли. Пока через несколько дней внезапно не отключился vCenter Server. Журнал приложений в Windows показал, что база vCenter заняла максимально возможные 10 Гб (в качестве СУБД мы используем Microsoft SQL Server 2008 R2 Express Edition), что, собственно, и послужило причиной остановки vCenter.
С помощью сценария мы быстро определили размер всех таблиц в базе.
SET NOCOUNT ON DBCC UPDATEUSAGE(0) -- DB size. EXEC sp_spaceused -- Table row counts and sizes. CREATE TABLE #t ( [name] NVARCHAR(128), [rows] CHAR(11), reserved VARCHAR(18), data VARCHAR(18), index_size VARCHAR(18), unused VARCHAR(18) ) INSERT #t EXEC sp_msForEachTable 'EXEC sp_spaceused ''?''' SELECT * FROM #t -- # of rows. SELECT SUM(CAST([rows] AS int)) AS [rows] FROM #t DROP TABLE #t
Самыми большими оказали таблицы VPX_EVENT и VPX_EVENT_ARG — вместе с индексами они занимали более 9.5 Гб. С кем не бывает — подумали мы, хотя и усомнились, т.к. наша тестовая лаборатория не такая большая, чтобы в журналах сохранялось так много событий. Для очистки таблиц мы использовали сценарий с сайта VMware:
TRUNCATE table VPX_EVENT_ARG DELETE FROM VPX_EVENT
Если вы планируете последовать нашему примеру — приготовьтесь к тому, что выполнение сценария потребует много времени и приведет к существенному увеличению размера журналов базы (в конце статьи приведен альтернативный сценарий). Поскольку в качестве Recovery Model установлен режим Simple, то после завершения операции мы сделали Shrink Database, и база уменьшилась до 350 Мб.
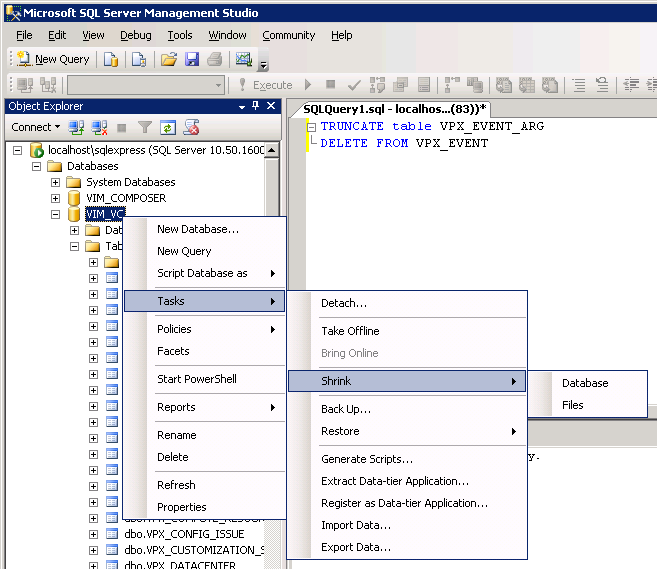
Однако, через некоторое время после включения служб vCenter база снова стала расти гигантскими темпами. Для определения причины проблемы заглянули vCenter Server log и обнаружили огромное количество записей о подключении vSphere Management Assistant к серверу vCenter.

Для проверки мы выключили на время виртуальную машину с vMA, и база перестала расти. Поскольку сам vMA был установлен достаточно давно, то стало понятно, что проблема возникла из-за недавних манипуляций с vilogger. Отключение сбора журналов с сервера vCenter позволило решить проблему. Уже потом, ища более простой способ очистки базы от событий, мы обнаружили, что не первые, кто столкнулся с данной проблемой, более того — есть соответствующая статья в базе знаний VMware. Вот код от vfrank.org:
alter table VPX_EVENT_ARG drop constraint FK_VPX_EVENT_ARG_REF_EVENT, FK_VPX_EVENT_ARG_REF_ENTITY alter table VPX_ENTITY_LAST_EVENT drop constraint FK_VPX_LAST_EVENT_EVENT truncate table VPX_TASK truncate table VPX_ENTITY_LAST_EVENT truncate table VPX_EVENT truncate table VPX_EVENT_ARG alter table VPX_EVENT_ARG add constraint FK_VPX_EVENT_ARG_REF_EVENT foreign key(EVENT_ID) references VPX_EVENT (EVENT_ID) on delete cascade, constraint FK_VPX_EVENT_ARG_REF_ENTITY foreign key (OBJ_TYPE) references VPX_OBJECT_TYPE (ID) alter table VPX_ENTITY_LAST_EVENT add constraint FK_VPX_LAST_EVENT_EVENT foreign key(LAST_EVENT_ID) references VPX_EVENT (EVENT_ID) on delete cascade
Вывод
Переполнение базы данных vCenter (VCDB) из-за vSphere Management Assistant и компонента vilogger — распространённая проблема. Основная причина — чрезмерный рост таблиц VPX_EVENT и VPX_EVENT_ARG из-за избыточных событий. Простая очистка таблиц даёт лишь временный эффект, но без устранения источника ситуация повторяется.
Надёжная стратегия включает три шага:
- Своевременный бэкап VCDB и контроль её размера.
- Поиск и отключение источников избыточных логов (чаще всего — vMA с включённым vilogger).
- Настройка ротации и автоматического удаления старых событий, а также обновление компонентов VMware до актуальных версий.
Такой подход позволит поддерживать стабильность работы vCenter и предотвратить простои из-за переполненной базы данных.
Варианты записей в логах при ошибке:
Ошибки, связанные с накоплением событий/задач от vMA
Event insertion failed: database disk space exhausted
TaskManager: Failed to log task 'QueryPerformance' from vMA - DB full
Too many events from client viClient=vMA - consider limiting or disabling logging
Сообщения в vpxd.log, указывающие на vMA
viClient=vMA
User=vpxuser from vMA host
Session initiated by vMA
2025-04-05T10:00:00.123Z error vpxd[7F1234567890] [Originator@6876 sub=Default] Failed to insert event: database is full --> Context: User=vpxuser, Client=viClient=vMA, IP=192.168.1.50
Ошибки PostgreSQL (если vCenter использует встроенную БД)
FATAL: could not write to file "pg_xlog/xlogtemp.12345": No space left on device
ERROR: could not extend file "base/16385/1234567": No space left on device HINT: Check free disk space.
FAQ
Почему база VCDB переполняется?
Чаще всего это происходит из-за накопления миллионов событий в таблицах VPX_EVENT и VPX_EVENT_ARG. Причиной может быть vSphere Management Assistant (vMA) с включённым vilogger, который генерирует слишком много записей.
Можно ли просто очистить таблицы событий?
Да, но это временное решение. После очистки база снова начнёт расти, если не устранить источник. Более надёжный способ — отключить vilogger, настроить ротацию событий и периодический purge старых данных.
Как проверить, виноват ли vMA?
Остановите vMA и понаблюдайте за ростом базы. Если рост прекращается — причина именно в vilogger. Также можно проанализировать логи vCenter на предмет повторяющихся запросов от vMA.
Что делать, если база снова растёт после очистки?
Необходимо устранить источник (чаще всего — vMA). Дополнительно настройте автоматическое удаление старых событий и используйте актуальные версии VMware, где часть проблемных компонентов исправлена.
Полезные ссылки
- Официальная KB VMware по отключению vilogger
- Разбор проблемы с переполнением VCDB (VMpress)
- Документация VMware vCenter (Broadcom TechDocs)
- Virtualization Review — полезные статьи о VMware и VCSA
Подробнее и спасибо: http://blog.vmpress.org/, http://citrix.pp.ru/